
WordPress robots.txt file is an important file for your website’s SEO efforts. It can have a powerful impact on index/de-index particular pages of your website. Google has evolved a lot about how it crawls the web and provides you with search results. The best practices from a few years ago often don’t work anymore. This post outlines how you can optimize your WordPress robots.txt file for better SEO.
What is robots.txt File?
In the world of the internet, bots are small pieces of software that visit websites on the Internet. The most common example is the search engine bots. These search engine bots “crawl”/scans around the web to help search engines organize data. Search engines like Google use these bots to index and rank your website against billions of pages on the Internet.
Quick Navigation
robots.txt is a text file that decides what search engines can index on your site.
So, bots are a good thing for the Internet. However, you might be thinking to yourself, if bots are great why should I worry about WordPress robots.txt file anyway?
Researchers found the need to control how bots interact with websites. This led to the creation of the robots exclusion standard in the mid-1990s. robots.txt file is the application of that standard.
The robots.txt file allows you to control how bots can interact with your site. It is a text file that you can create at your root folder to let search engines know what you are allowing to index. You can enable access to every page of your website by granting unrestricted access to bots, can block entirely or restrict bot’s access to individual pages and subdirectories of your website.
If you want to restrict bad bot accessing your websites, you can use security solution services such as Cloudflare or Incapsula can come in handy.
Why Should You Have a robots.txt File?
Well, it’s obvious. robots.txt plays a crucial part in SEO. One of our readers asked what is robots.txt in SEO so that we will be outlining the answer as well.
- One of the significant advantages of
robots.txtfile is that you can command search engines’ to crawl resources what you want. You can write rules you don’t wish to be crawled. This helps to ensure that search engines can index the contents you care about. - Optimizing server resources by blocking malicious bots that could waste computational resource on your server.
By disallowing additional pages, you can make efficient use of your crawl quota. This helps search engines crawl only selected pages on your site and index them as soon as possible.
What is the Best robots.txt File?
There are a few formats you can follow. Additionally, you can use a robots.txt Generator tool too. After generating, you have to make sure you upload the robots.txt file to the root (public_html folder in the case cPanel hostings)
Ideal WordPress robots.txt – Example #1
User-agent: *
Disallow:
Sitemap: http://www.example.com/sitemap_index.xml- This sitemap allows every bot.
- Does not disallow any bot.
- Gives a link to the website’s sitemap. Here is the
robots.txtfile we are using.

Sitemap link plays a significant role in the overall SEO presence of your website, as mentioned in our WordPress SEO Guide.
You can also use disallow tags like the following to restrict access to individual pages of your website.
Disallow: /wp-admin/
Disallow: /wp-login.phpOptimal WordPress robots.txt – Example #2
Here’s another ideal WordPress robots.txt file for your convenience. This sitemap restricts access to WordPress core folders but allows all other front pages to be indexed. Also links sitemap for search engine’s convenience.
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap_index.xmlHow To Create Different Rules For Different Bots In robots.txt
You can create different rules for different bots. For example, if you want only Google bots to access some parts of the page, you can specify that. If you’re going to block Google bot and allow bing bot, you can do that too.
You can specify rules under the User-agent statement for each bot. For example, if you want to make one rule that applies to all bots and another rule that applies to just Googlebot, you could do it like this:
User-agent: *
Disallow: /wp-admin/
User-agent: Googlebot
Disallow: /Here,
- * means for all bot. (* is used in Regular Expression as well). Whatever you write for user-agent: * will be applied for all bots.
- User-agent: Googlebot specifies the user-agent. Whatever rules you add here will be applied only for Googlebot.
How To Test If Your robots.txt Working?
After placing your robots.txt file to your root directory, you should check a few times to ensure that the file is working as intended. I will be showing two different methods to test your robots.txt file.
Check WordPress robots.txt from /robots.txt
- If your website’s name is example.com, you should be able to access your
robots.txtfile from example.com/robots.txt. If it’s not loading then you are not uploading the file to the correct location. - If you find out the file is loading correctly in the browser, you can half ensure that it is working. But you must also ensure that Google is receiving a proper HTTP response.
- Again navigate to your website’s
robots.txtURL and Press Ctrl+Shif+J to open up the console. Click “Network.” And reload your website.
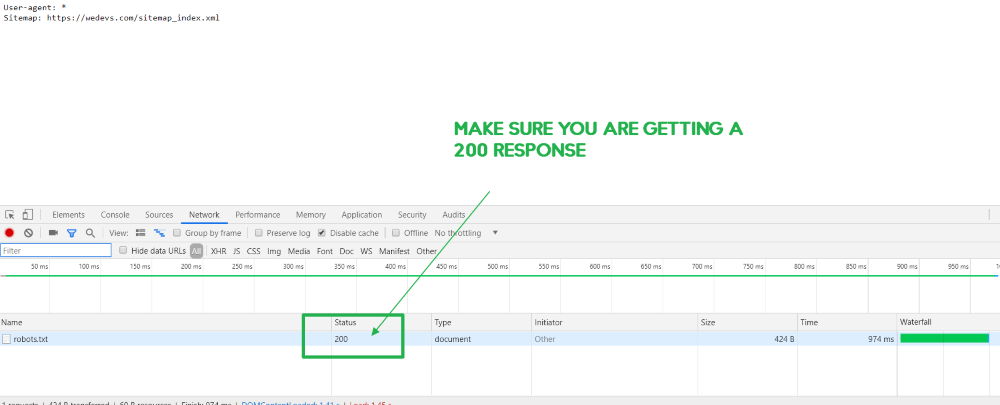
Check robots.txt
robots.txt- Log into Google Search Console
- Navigate to the old version of the tool and under Crawl → Fetch as Google, use the Fetch and Render option:

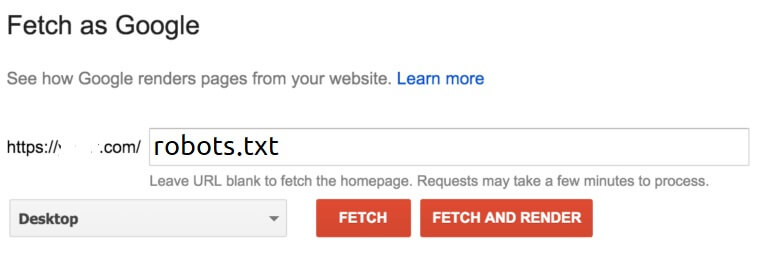
Click and fetch and render and notice if there are any issues.
Wrapping Up on robots.txt
robots.txt help search engines understand your website well. Google is rapidly evolving towards an AI-powered future. The advancements in AI is going on a rapid speed. Google is nurturing its search algorithm using AI and Machine Learning gradually.
robots.txt can help search engines to make better decisions. The search engine will not crawl if you disallow pages.
Do not be confused with robots.txt Disallow with noindex tag. robots.txt blocks crawling, but not indexing. You can use it to add specific rules to control how search engines and other bots interact with your site. Nevertheless, it will not explicitly control whether your content is indexed or not.


Add your first comment to this post